TL;DR — Semantic vs. Instance Segmentation (Microscopy). Semantic segmentation labels every pixel by class (e.g., cell, grain, background). Instance segmentation goes further by separating each object (each cell or grain) into a unique mask, enabling counts and per-object measurements.

Figure 1. Demonstration of how Semantic vs. Instance Segmentation impacts area vs. object identification in images.
Segmentation is the foundation of AI-powered microscopy. In our AI Essentials Guide, we highlighted segmentation as a core task where artificial intelligence excels. But what exactly are the differences between semantic segmentation and instance segmentation, and why does it matter for your research?
This article provides a deep dive into both approaches, explaining how they work “under the hood,” and showing where they fit across life science and materials applications. By the end, you’ll know which approach aligns with the question of coverage vs counts, and how today’s techniques may evolve in the future.
What Is Image Segmentation in Microscopy?
Segmentation transforms raw pixels into meaningful structures. Instead of viewing an image as a matrix of intensities, segmentation partitions it into scientifically relevant objects such as cells, nuclei, grains, fibers, or background.
This transformation is what makes measurements possible because you can’t count cells, calculate grain size, or track particle distributions until you’ve defined what belongs where.
Semantic Segmentation in Microscopy: Pixel-Level Classification
Definition
Semantic segmentation assigns every pixel in an image to a predefined class label (e.g., cell, grain, background). All objects of the same type are merged into one “semantic” region.

Figure 2. Semantic segmentation groups all structures of the same type under a single label, such as the "Glass Fibers" above.
How It Works (Under the Hood)
Most semantic segmentation algorithms are built on what’s called a fully convolutional network (FCN), which is a type of deep learning model designed to handle images of any size. A common version of this is the encoder–decoder design, seen in popular architectures like U-Net, introduced by Ronneberger et al. in 2015.
The encoder acts like a scanner: it gradually reduces the image into simpler representations, stripping away detail while keeping the most important features (like outlines or textures).
The decoder then works in reverse: it rebuilds the image back to its original size, adding class labels (e.g., cell, background) to every pixel.
To avoid losing fine detail, U-Net uses skip connections, which are direct shortcuts that bring back high-resolution information from the encoder and feed it into the decoder.
This combination means the network can both “see the big picture” and “preserve the small details,” making it especially effective in microscopy where cell boundaries are faint or hard to distinguish.
A recent review of deep learning in the
Journal of Imaging highlights this encoder–decoder + skip-connection pattern as the dominant design in modern semantic segmentation, particularly in microscopy contexts.
Strengths
- Accurate for measuring coverage (e.g., % of dish covered by cells, % porosity in metal foams).
- Robust in low-contrast regions where borders are less critical.
- Simpler annotations and generally faster training.
Limitations
- Cannot distinguish individual objects if they overlap, leading to clusters becoming one region.
For a quick refresher on how convolutional layers extract features, see our primer on AI Essentials: CNNs in Microscopy.
Examples
- Life Science — Determining the fraction of a culture plate covered by cells (confluence assay).
- Materials & Industry — Measuring the fraction of a polished steel micrograph occupied by pearlite vs. ferrite, or estimating void fraction in a polymer composite.
Instance Segmentation in Microscopy (Cellpose, StarDist, & Beyond)
Definition
Instance segmentation assigns class labels to pixels and separates different objects of the same class. Two nuclei in contact receive distinct IDs, enabling counting and per-object measurements.

Figure 3. Instance segmentation distinguishes and labels each object individually as shown with the color-coded fibers above.
How It Works (Under the Hood)
When it comes to instance segmentation, there are two main strategies that algorithms use:
1. Detection-first methods (e.g., Mask R-CNN)
These start by drawing bounding boxes (rectangles) that roughly locate where each object might be. Once the boxes are placed, the algorithm creates a more detailed pixel mask inside each box to outline the object’s shape.
This approach works well in general computer vision (like detecting cars or people in photos), but in microscopy, where you might have hundreds of overlapping cells or grains, drawing boxes first can become inefficient and less precise.
2. Shape/flow-based methods
Instead of using boxes, these methods predict fields or shapes that directly define the objects. Think of it as drawing the object outlines from the inside out rather than cutting them from boxes. This is especially useful in microscopy, where objects are often roundish, irregular, or tightly packed.
Two widely used open-source tools illustrate this second strategy:
1. Cellpose (flow-field integration)
Cellpose, introduced by Stringer et al. in 2020, predicts vector flows made up of arrows that point from each pixel toward the center of its object. When you follow these arrows, pixels naturally cluster together into separate objects.
Because it was trained on a wide variety of images, Cellpose often works out of the box for many microscopy datasets. This “flow-field” idea is powerful because it helps separate touching cells or particles without relying on bounding boxes.
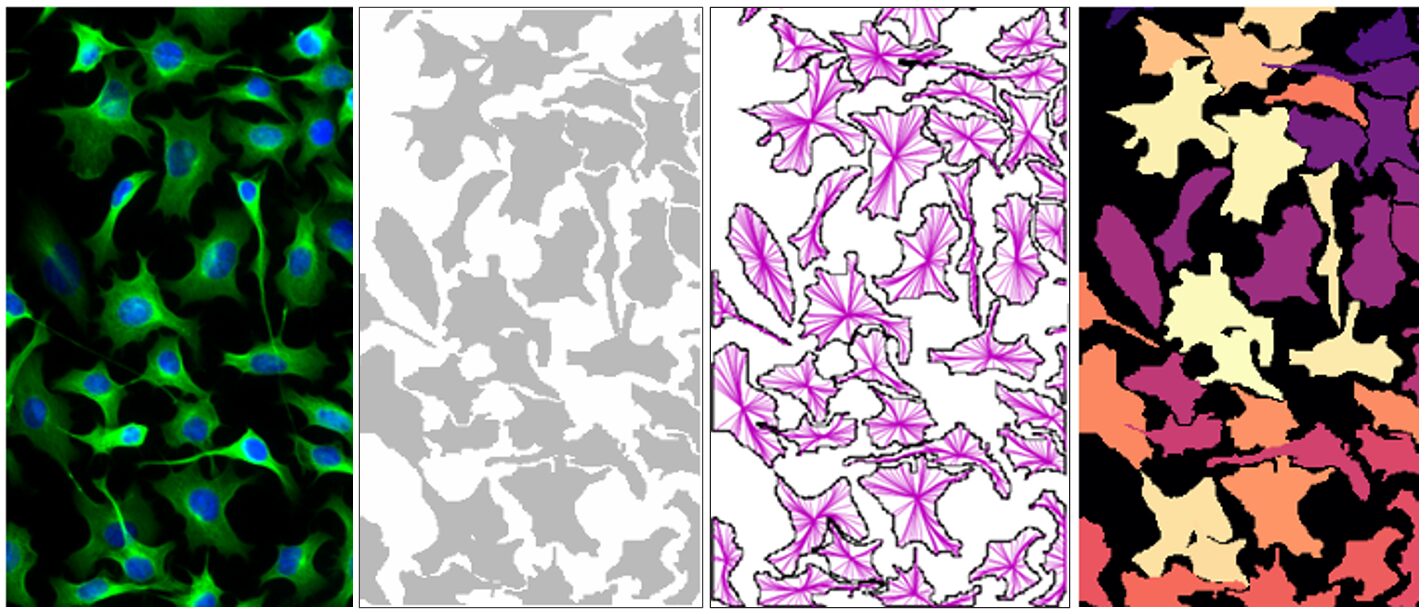
Figure 4. Example of Cellpose. Source: [Stringer et al., 2020, Nature Methods]
StarDist (star-convex polygons)
StarDist, introduced by Schmidt et al. in 2018, represents each object as a star-convex polygon, which is a geometric shape that can be drawn by shooting out rays from the object’s center and marking how far they go before hitting the edge.
The algorithm predicts these distances for dozens of rays per object, then stitches them together into a polygon mask. This approach is especially effective for blob-like structures (such as nuclei or grains), producing masks that are both clean and interpretable.
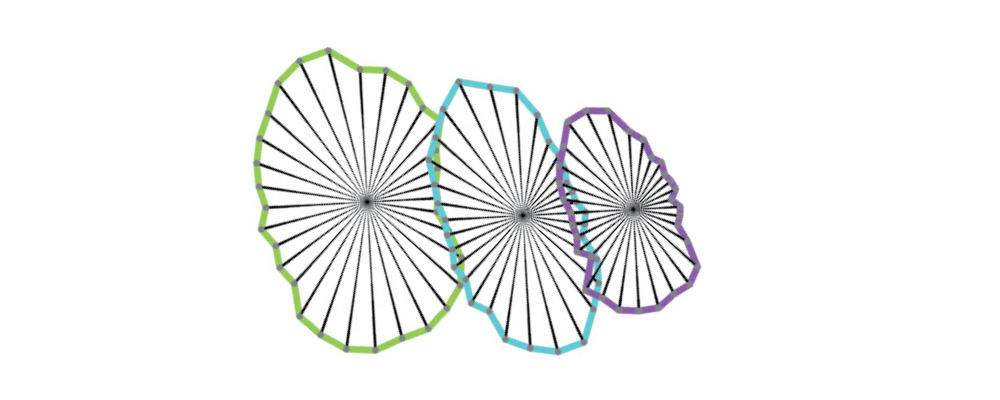
Figure 5. Example of StarDist.
Overlapping objects and inconsistent boundaries are some of the classic pain points discussed in our article, Frustrating Realities of Image Analysis. Instance methods like these can directly address those challenges and overcome some of the frustrations.
Strengths
- Enables counting and per-object feature extraction (size, shape, intensity).
- Handles overlapping (StarDist) or touching objects (both) effectively.
- Supports morphometric analysis where individual identity matters.
Limitations
- Requires per-object annotations for training.
- More computationally demanding than semantic segmentation.
Examples
- Life Science — Counting individual tumor nuclei in crowded histology slides, or segmenting neurons for morphology studies.
- Materials & Industry — Measuring grain size distribution in steel (ASTM E112), separating overlapping ceramic particles, or identifying solder voids in semiconductor inspection.
Future of Instance Segmentation in Microscopy Research and Industrial Inspection
While Cellpose and StarDist are two of today’s leading open-source tools, it’s important to see them as examples of algorithmic strategies rather than permanent fixtures.
- The flow-field concept (Cellpose) could inspire future algorithms that combine vector fields with attention mechanisms or diffusion models to better handle irregular structures.
- The polygonal concept (StarDist) could evolve into models that generate more flexible, non-convex shapes or even hierarchical object boundaries for multi-scale materials analysis.
- Hybrid approaches are already emerging, blending detection, shape prediction, and learned priors from large-scale vision models.
As datasets expand and AI models grow more general, it’s reasonable to expect new algorithms that surpass today’s leaders. But the principles of instance segmentation as object-level separation and semantic segmentation as class-level labeling, will remain the same.
Semantic vs. Instance Segmentation: Side-by-Side Comparison Table

Figure 6. Visual comparison: semantic segmentation groups objects; instance segmentation separates each object individually.
| Feature | Semantic Segmentation | Instance Segmentation (General) | Example: Flow-field (Cellpose) | Example: Polygon (StarDist) |
|---|---|---|---|---|
|
Output |
Per-pixel class labels |
Per-pixel labels + unique IDs |
Instances via flow integration |
Instances via star-convex polygons |
|
Handles Overlap? |
❌ No |
🌓 Sometimes |
❌ No |
✅ Yes |
|
Typical Base |
U-Net-style encoder–decoder |
Detection-first or shape/flow |
Flow fields + probability maps |
Ray distances + object probability |
|
Best For |
Coverage, broad classification |
Counting, per-object metrics |
Heterogeneous modalities |
Blob-like, crowded objects |
|
Use Cases |
Cell confluence, porosity fraction |
Counting, sizing, morphology |
Cross-modality cell segmentation |
Nuclear/grain segmentation |
Table 1. Direct comparison: semantic segmentation (all grouped) vs instance segmentation (objects separated).
How to Choose Between Semantic and Instance Segmentation in Microscopy
- Use semantic segmentation when your research goal is coverage, distribution, or general classification (e.g., % tissue coverage, % porosity in alloys).
- Use instance segmentation when you need counts, distributions, or per-object shapes (e.g., cell proliferation rates, grain size histograms, particle size distributions).
- Think ahead — Current exemplars like Cellpose and StarDist are great starting points, but similar methods (flow-based, polygon-based, or yet-to-be-developed) will continue to improve. The choice should be driven by the research question, not allegiance to a single tool.
Key Takeaways: Semantic vs Instance Segmentation in Microscopy Research and Materials Analysis
- Semantic segmentation — when your research goal is coverage, distribution, or general classification (e.g., % tissue coverage, % porosity in alloys).
- Instance segmentation — object separation; essential for counting and morphology. Techniques like flow-field integration (Cellpose) and star-convex polygons (StarDist) illustrate how current algorithms tackle this challenge.
- Future-proof perspective — While today’s tools may change, the conceptual divide between semantic and instance segmentation remains. It is important to align the method with research goals and choose the simplest model that achieves those goals reliably and consistently.
Frequently Asked Questions
Semantic segmentation labels every pixel by class (e.g., cell vs. background, grain vs. matrix). Instance segmentation goes further, separating individual objects, which is essential for cell counts or grain size measurements.
Flow-field methods are strong when you need robustness across heterogeneous data and don’t want to rely on bounding boxes. They are especially good for varied cell types, irregularly shaped particles, or noisy imaging conditions.
Star-convex polygon approaches excel when the objects of interest are relatively round or convex—such as nuclei, grains, or certain particles. They produce masks that align closely with expected object geometries.
No. They are examples of current leading methods, but the underlying ideas (flows and polygons) are part of a broader landscape. New methods (including transformer-based, diffusion-based, or hybrid approaches) are likely to emerge.
The same principles apply in materials and industrial inspection: semantic segmentation for porosity or coverage, instance segmentation for individual grains, particles, or defects.
Semantic segmentation = “what class is where.”
Instance segmentation = “which object is which.”


Media Cybernetics
sales@mediacy.com
Related Links